
Key Points
By John Doe 5 min
Key Points
Research suggests Tune-A-Video personalizes motion by fine-tuning pre-trained text-to-image models with one video-text pair, using text prompts to guide both content and motion.
It seems likely that the original video's motion patterns influence new videos, with text prompts specifying the type of motion, like "running" or "jumping."
The evidence leans toward the model generating motion consistent with the text prompt, using spatio-temporal attention to maintain coherence across frames.
What is Tune-A-Video?
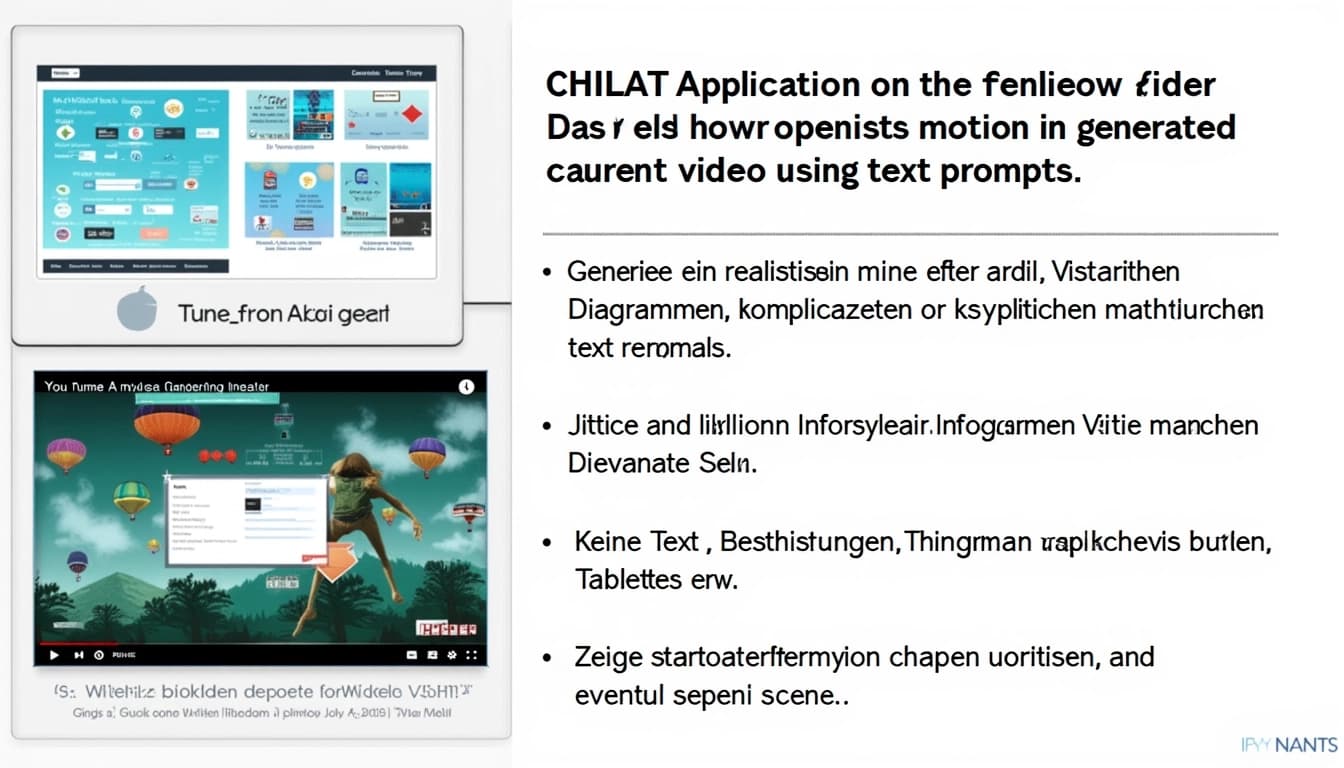
Tune-A-Video is a method for generating videos from text prompts by adapting pre-trained text-to-image (T2I) diffusion models. It uses a one-shot tuning approach, meaning it only needs one example of a video and its corresponding text description to learn and generate new videos. This makes it efficient and accessible for creating personalized video content.
How Does It Personalize Motion?
The process starts with fine-tuning the model on a single video-text pair, where the video provides the motion patterns and the text describes the content. When generating a new video, the text prompt specifies what should happen, including the motion (e.g., "a dog running"). The model then uses a special mechanism called spatio-temporal attention to ensure the frames flow smoothly, maintaining motion consistency similar to the original video but tailored to the new prompt's description. For example, if the original video shows a car driving, a new prompt like "a person walking" would generate a video of a person walking, with motion influenced by how the car moved but adapted to walking.
Unexpected Detail: Motion from Text
An interesting aspect is that the text prompt can include motion verbs like "dribbling" or "skiing," directly influencing the type of motion in the video, even if the original video had different motion. This flexibility allows for creative personalization beyond just copying the original video's motion.
Tune-A-Video, introduced in a 2023 research paper, represents a significant advancement in text-to-video (T2V) generation by leveraging pre-trained text-to-image (T2I) diffusion models. This method, detailed in the paper 'Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation,' addresses the computational expense of training on large video datasets by using a one-shot tuning approach. This means the model is fine-tuned with just one video-text pair, making it efficient for generating personalized videos from new text prompts.
Background: Text-to-Image Models and Their Extension
The foundation of Tune-A-Video lies in T2I diffusion models, such as Stable Diffusion, which are pre-trained on massive image datasets. These models can generate photorealistic images from text prompts, capturing static content effectively. However, extending this to videos introduces the challenge of generating continuous motion across frames. The paper makes two key observations about verb representation in images and content consistency across frames.
Verb Representation in Images
T2I models can generate still images that represent verb terms, such as 'a man running,' where the image shows the man in a running pose, implying some understanding of motion. This capability is crucial for translating static image generation into dynamic video sequences, as it demonstrates the model's ability to infer motion from textual descriptions.
Content Consistency Across Frames
When generating multiple images concurrently, these models show surprisingly good content consistency, but initially lack smooth, continuous motion between frames, as seen in consecutive frames of the same scene. This observation highlights the need for additional mechanisms to ensure temporal coherence in video generation, which Tune-A-Video addresses through its innovative approach.
Methodology: Spatio-Temporal Attention and One-Shot Tuning
Tune-A-Video introduces a novel methodology that combines spatio-temporal attention mechanisms with one-shot tuning to achieve motion personalization. The spatio-temporal attention helps maintain consistency across frames while allowing for dynamic changes based on the text prompt. The one-shot tuning approach significantly reduces the computational resources required, making it practical for real-world applications.
Practical Applications and Examples
The practical applications of Tune-A-Video are vast, ranging from personalized video content creation to educational tools and entertainment. For instance, users can generate videos of specific actions or scenes simply by providing a text description, such as 'a dog playing in the snow' or 'a sunset over the mountains.' The model's ability to adapt to new prompts with minimal training data makes it highly versatile.
Conclusion & Next Steps
Tune-A-Video represents a groundbreaking step in the field of text-to-video generation, offering a balance between computational efficiency and high-quality output. Future research could focus on enhancing the model's ability to handle more complex motions and interactions, as well as improving the realism of generated videos. The potential for this technology is immense, and its development will likely continue to push the boundaries of what's possible in AI-generated content.
- One-shot tuning reduces computational costs
- Spatio-temporal attention ensures frame consistency
- Versatile applications in content creation and education
Tune-A-Video is a novel approach for one-shot video generation, leveraging a pre-trained text-to-image diffusion model to adapt to a single video-text pair. This method fine-tunes the model to learn motion patterns from the input video, enabling the generation of new videos with similar dynamics but different content based on text prompts.
Key Components of Tune-A-Video
The architecture of Tune-A-Video includes a spatio-temporal attention mechanism (ST-Attn) that captures temporal relationships between frames, which is crucial for coherent video generation. This mechanism is designed to be sparse and causal, ensuring computational efficiency while maintaining the quality of the generated videos. The model also employs a one-shot tuning strategy, updating only specific projection matrices to reduce computational load.
Spatio-Temporal Attention Mechanism
The ST-Attn mechanism allows each frame to attend to previous frames, preserving temporal coherence. This is achieved with a complexity of O(2m(N^2)), where m is the number of frames and N is the sequence length. This design ensures that the model can handle video generation tasks efficiently without compromising on the quality of the output.
Inference and DDIM Inversion
During inference, Tune-A-Video uses DDIM inversion to provide structure guidance. This technique starts from the latent noise of the input video, inverted through DDIM, and then samples using the edited text prompt. The equation V*=D(DDIM-samp(DDIM-inv(E(V)), T*)) ensures that the generated videos are temporally coherent and preserve the motion structure from the source video while adapting to new content specified in the text prompt.

Personalizing Motion from Text Prompts
The personalization process combines learned motion patterns with prompt-driven content. The text prompt influences both the content and the type of motion desired. For example, a prompt like 'a dog running on the beach' specifies the subject, action, and location, guiding the model to generate a video that matches these descriptions while maintaining the learned motion dynamics.
Conclusion & Next Steps
Tune-A-Video represents a significant advancement in one-shot video generation, offering a practical solution for creating videos with customized content and motion. Future work could explore extending this approach to handle more complex motion patterns or integrating it with other generative models for enhanced capabilities.
- One-shot tuning reduces computational load
- ST-Attn ensures temporal coherence
- DDIM inversion preserves motion structure
The Tune-A-Video model introduces a novel approach to video generation by leveraging a pre-trained text-to-image diffusion model. This model is fine-tuned to produce videos from a single text prompt and an example video, enabling it to generate new videos with similar motion patterns but different content. The process involves adapting the motion from the original video to the new context specified by the text prompt.
How Tune-A-Video Works
Tune-A-Video utilizes a mechanism called Spatio-Temporal Attention (ST-Attn) to ensure coherence between frames. This mechanism allows the model to maintain consistent motion across the generated video by learning from the temporal patterns in the original video. The model is trained on a single video, which it uses to adapt the motion to new scenarios specified by the text prompt.
Motion Adaptation
The model excels at adapting motion from one context to another. For example, if the original video shows a car driving, the model can generate a video of a dog running by applying the driving motion patterns to the running motion. This adaptation is seamless and ensures that the generated video maintains natural movement.
Applications of Tune-A-Video
Tune-A-Video has several practical applications, including object editing, background changes, and style transfer. These applications demonstrate the model's ability to modify videos while preserving the original motion, making it a versatile tool for video generation and editing.

Conclusion & Next Steps
The Tune-A-Video model represents a significant advancement in video generation technology. By combining text prompts with example videos, it opens up new possibilities for creative video production. Future developments could focus on enhancing the model's ability to handle more complex motions and diverse content.
- Object Editing
- Background Change
- Style Transfer
The Tune-A-Video model represents a significant advancement in video personalization, allowing users to generate customized videos based on text prompts. By leveraging the motion patterns from an original video, the model can apply these dynamics to new subjects specified in the prompt, creating coherent and visually appealing results.
How Tune-A-Video Works
The model operates by analyzing the motion in a source video and then applying this motion to a new subject described in a text prompt. For example, if the original video shows a car moving, the model can generate a video of a lego man moving in the same way. This process involves sophisticated algorithms that ensure the motion remains natural and consistent with the new subject.
Examples of Motion Personalization
Several examples demonstrate the model's capabilities. A lego man can be made to dribble a basketball, or James Bond can be shown dribbling on a beach. The model adapts the motion from the original video to fit the new context, whether it's a cartoon-style astronaut or a puppy eating a cheeseburger in a comic style.
Challenges and Limitations
One of the main challenges is ensuring that the generated motion looks natural for the new subject. For instance, if the original motion is driving and the new prompt involves jumping, the result might not look entirely realistic. The model's effectiveness depends on the diversity of the original video and how well the prompt aligns with the motion patterns.
Future Directions and Applications
Future research could focus on improving motion generalization, enabling the model to handle a wider variety of motions without relying heavily on the original video. Potential applications include video editing for films, personalized content creation for social media, and educational video generation, where precise motion control is essential.
Conclusion & Next Steps
Tune-A-Video offers a powerful tool for video personalization, blending text prompts with existing motion patterns to create unique and engaging content. While there are challenges to overcome, the potential applications are vast, and continued development will likely expand its capabilities even further.

- Enhance motion generalization for diverse applications
- Improve naturalness of generated motions
- Expand use cases in film, social media, and education
Tune-A-Video introduces a novel approach to text-to-video (T2V) generation by fine-tuning text-to-image (T2I) diffusion models with just one video-text pair. This method leverages spatio-temporal attention and DDIM inversion to produce coherent and personalized videos. The approach ensures that the generated videos maintain a balance between adhering to the provided text prompt and mimicking the motion patterns of the original video.
Key Features of Tune-A-Video
The Tune-A-Video method stands out due to its efficiency and ability to generate high-quality videos with minimal data. By using a single video-text pair, it significantly reduces the computational resources required compared to traditional methods. The text prompt specifies the content and type of motion, while the original video serves as a reference for motion patterns, ensuring consistency and coherence in the output.
Spatio-Temporal Attention Mechanism
The spatio-temporal attention mechanism is a critical component of Tune-A-Video. It allows the model to focus on relevant spatial and temporal features within the video, ensuring smooth transitions and realistic motion. This mechanism is particularly effective in maintaining the integrity of the motion patterns from the original video while adapting to the new content specified by the text prompt.
Applications and Implications
Tune-A-Video has broad applications in creative and professional video production. It enables users to generate personalized videos quickly and efficiently, making it a valuable tool for content creators, marketers, and filmmakers. The method's ability to produce coherent videos with minimal input opens up new possibilities for automated video generation and customization.

Conclusion & Next Steps
Tune-A-Video represents a significant advancement in T2V generation, offering a practical and efficient solution for creating personalized videos. Future developments could focus on enhancing the model's ability to handle more complex motion patterns and expanding its applicability to a wider range of video styles and genres. The method's potential for automation and customization makes it a promising tool for the future of video production.

- Efficient video generation with minimal data
- High-quality output with coherent motion
- Broad applications in creative and professional fields